자바에서 가장 많이 사용하는 컬렉션 중 하나가 바로 ArrayList입니다. ArrayList는 크기를 동적으로 조절해주기 때문에 편리하지만, 내부 구조나 특성을 모른채 사용하면 성능 저하나 런타임 에러를 겪을 수 있습니다.
이 글에서는 ArrayList의 기본 개념 및 내부 구조와 동작원리 부터, 사용시 꼭 알아야 할 주의사항까지 한번에 정리해 보도록 하겠습니다.
01. ArrayList란 무엇인가?
ArrayList는 배열을 기반으로 한 컬렉션의 하나이며. 일반 배열과 달리 초기 크기를 지정하지 않아도 데이터 추가에 따라 자동으로 용량이 늘어나는 편리함을 제공하며 다음과 같은 특징을 가지고 있습니다.
- ✔ 데이터 순서 유지
- ✔ 중복 데이터 허용
- ✔ 인덱스 기반의 빠른 접근 가능
- ✔ 크기 자동 증가(동적 배열)
- ✔ 스레드 안전하지 않음
ArrayList는 편리하지만, 모든 상황에 적합한 자료구조는 아닙니다.
02. 내부 구조와 동작 원리
ArrayList는 데이터를 추가, 삭제시 내부에서 동적으로 배열의 길이를 조절해 줍니다. ArrayList를 생성하게 되면 내부에서는 데이터를 저장하기 위한 Capacity 크기의 저장공간이 할당되며, 사용중 데이터의 크기가 이 Capacity의 크기를 넘어서게 되면 저장공간이 새롭게 할당됩니다.
1) 왜 조회(get)는 빠를까?
ArrayList는 배열 기반으로, 인덱스로 바로 접근하기 때문에 조회가 빠릅니다.
- 시간 복잡도 : O(1)
2) 왜 중간 삽입,삭제는 느릴까?
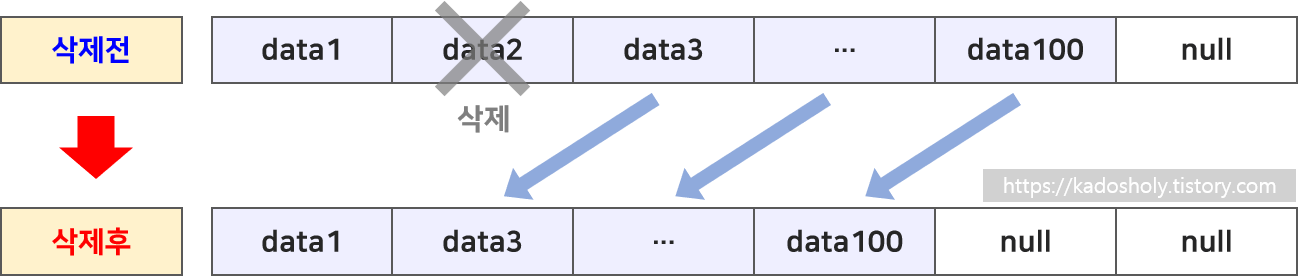
배열이기 때문에 데이터 중간에 삽입이나 삭제가 일어날 경우 요소의 이동이 발생합니다.
- 시간 복잡도 : O(n)
03. ArrayList vs 배열 / LinkedList
1) ArrayList vs 배열
배열은 길이가 고정된 반면 ArrayList는 배열의 길이를 자동으로 조절해주는 기능이 있어 가변 크기의 데이터라면 ArrayList가 압도적으로 유리합니다.
| 구 분 | ArrayList | 배열 |
| 크기 변경 | 자동 확장 | 고정 |
| 편의성 | 높음 | 낮음 |
| 성능 | 약간 느림 | 빠름 |
2) ArrayList vs LinkedList
ArrayList는 내부적으로 배열을 기반으로 하기 때문에 데이터의 위치 정보를 바로 알 수 있어 데이터를 읽는 속도가 LinkedList에 비해 매우 빠릅니다. 따라서 데이터 조회가 많으면 ArrayList가 유리하며, 삽입과 삭제가 빈번한 경우에는 데이터의 이동없이 연결정보만 가지고 있는 LinkedList가 더 효율적입니다.
| 구 분 | ArrayList | LinkedList |
| 내부 구조 | 배열 (Array) | 이중 연결 리스트 (Node) |
| 조회 | 빠름 (인덱스로 접근) |
느림 (순차 탐색) |
| 맨앞 데이터 삽입/삭제 | 느림 (기존 데이터 밀어냄) |
빠름 (연결만 변경) |
| 중간 데이터 삽입/삭제 | 느림 (기존 데이터 밀어냄) |
상대적 빠름 (탐색 비용 발생) |
| 맨뒤 데이터 추가/삭제 | 빠름 (순차적 작업) |
빠름 (연결만 변경) |
💡 LinkedList 중간 삽입시 '상대적 빠름'이라고 표현한 이유는 삽입 위치를 찾은 후의 '연결 변경' 과정이 ArrayList의 '데이터 밀어내기' 보다 비용이 적기 때문입니다. 하지만 데이터 양이 적다면 ArrayList가 더 빠를 수도 있다는 점에 유의하세요!>
04. ArrayList 생성방법
List<String> a1 = new ArrayList<>( ); // 기본 capacity는 10
List<String> a2 = new ArrayList<>(50); // 초기 capacity를 50으로 설정
List<String> a3 = new ArrayList<>(a1); // 다른 컬렉션(a1)의 데이터를 초기값으로 설정
ArrayList를 사용할때 capacity 크기를 지정하지 않으면 Default Capacity 값인 10 이 지정됩니다.
ArrayList는 공간이 꽉 찰 때마다 배열의 크기를 늘리고 복사하는 과정을 거치게 됩니다. 따라서 사용하게 될 데이터의 크기를 미리 산정하여 초기 용량(Capacity) 값을 지정하게 되면 이러한 resizing에 따른 성능 저하를 막을 수 있습니다.
💡여기서 잠깐! 왜 ArrayList<String> a1 = 대신 List<String> a1 = 으로 선언하나요?
이는 다형성 때문입니다. 나중에 성능상의 이유로 LinkedList로 구현체를 바꿔야 할 때, 변수 타입을 List로 해두면 나머지 코드를 수정할 필요가 없어 유지보수가 매우 유연해집니다.
05. ArrayList 메소드
1) 데이터 추가
- boolean add(E e) : 리스트의 끝에 데이터 e를 추가합니다.
- void add(int index, E element) : index의 위치에 데이터 element를 추가합니다.
- boolean addAll(Collection<? extends E> c) : 리스트의 끝에 컬렉션 c의 모든 데이터를 추가합니다.
- boolean addAll(int index, Collection<? extends E> c) : index의 위치에 컬렉션 c의 모든 데이터를 추가합니다.
2) 데이터 삭제
- void clear( ) : 리스트의 모든 데이터를 삭제합니다.
- E remove(int index) : index의 위치에 있는 데이터를 삭제합니다.
- boolean remove(Object o) : 리스트에서 Object o와 처음 일치하는 데이터를 삭제합니다.
- boolean removeAll(Collection<?> c) : 리스트에서 컬렉션 c와 일치하는 모든 데이터를 삭제합니다.
- boolean retainAll(Collection<?> c) : 리스트에서 컬렉션 c와 일치하는 데이터만 남기로 나머지는 삭제합니다.
3) 데이터 조회 및 확인
- int size( ) : 리스트의 데이터 개수를 반환합니다.
- boolean isEmpty( ) : 리스트가 비어있는지 여부를 반환합니다. (비어있을 경우 true)
- boolean contains(Object o) : Object o가 포함되어 있는지 여부를 반환합니다. (포함된 경우 true)
- int indexOf(Object o) : Object o와 처음 일치하는 데이터의 index 정보를 반환합니다. (없을경우 -1 반환)
- int lastIndexOf(Object o) : Object o와 마지막으로 일치하는 데이터의 index 정보를 반환합니다. (없을경우 -1 반환)
4) 데이터 반환
- E get(int index) : 리스트에서 index의 위치에 있는 데이터를 반환합니다.
- Object[ ] toArray( ) : 리스트의 모든 데이터가 포함된 Object 배열을 반환합니다.
- <T> T[ ] toArray(T[ ] a) : 리스트의 모든 데이터를 배열 a에 담은 후 배열 a를 반환합니다.
5) 데이터 수정 및 변경
- E set(int index, E element) : index의 위치에 있는 데이터를 element로 변경합니다.
6) 기타
- void trimToSize( ) : 리스트의 현재 size로 capacity를 조절합니다.
06. 사용예제
1) ArrayList 생성 및 실행
class Main {
public static void main(String[] args) {
List<String> a1 = new ArrayList<>();
a1.add("a");
a1.add("b");
a1.add("a");
a1.add("c");
a1.add(1, "A");
for (String s: a1) {
System.out.print(s + "-");
}
System.out.println("");
System.out.println("[1]: " + a1.isEmpty());
System.out.println("[2]: " + a1.size());
System.out.println("[3]: " + a1.contains("A"));
System.out.println("[4]: " + a1.indexOf("a"));
System.out.println("[5]: " + a1.lastIndexOf("a"));
System.out.println("[6]: " + a1.get(2));
System.out.println("[7]: " + a1.set(2, "z"));
System.out.println("[8]: " + a1);
System.out.println("[9]: " + a1.remove(3));
System.out.println("[10]: " + a1);
for (int i=a1.size()-1; i >= 0; i--) {
a1.remove(i);
}
System.out.println("[11]: " + a1);
}
}2) 실행결과
a-A-b-a-c-
[1]: false
[2]: 5
[3]: true
[4]: 0
[5]: 3
[6]: b
[7]: b
[8]: [a, A, z, a, c]
[9]: a
[10]: [a, A, z, c]
[11]: []07. 꼭 알아야 할 주의사항
- ConcurrentModificationException (가장 빈번함)
: 리스트를 for-each문(Iterator 기반)으로 순회하는 도중 구조적 변경(add, remove)이 발생하면, 내부의 fail-fast Iterator가 변경을 감지하고 ConcurrentModificationException을 발생시킵니다. - 멀티스레드 환경에서의 동기화 문제
: ArrayList는 스레드 안전(Thread-Safe)하지 않습니다. 여러 스레드가 동시에 데이터를 넣으려고 하면 데이터가 유실되거나 인데스 오류가 발생합니다. - 초기 용량(Capacity) 미지정
: 앞서 언급했지만 데이터 증가시, resizing 반복 발생하여 성능이 저하됩니다.
ArrayList는 단일 스레드 환경에서 조회가 잦고, 데이터 순서가 중요할 때 사용됩니다 반대로 멀티스레드 공유 자원이나 데이터의 중간 삽입/삭제가 잦은 경우에는 사용을 피해야 합니다. 따라서 단순히 "편해서 쓰는 자료구조"가 아니라 "특성을 이해하고 선택해야 하는 자료구조"란 점을 기억하시기 바랍니다.
'Java' 카테고리의 다른 글
| 이클립스 다운로드 및 설치방법 (Eclipse) (0) | 2026.03.24 |
|---|---|
| [Java] 자바 버전 확인방법 (JDK 버전) (0) | 2026.03.24 |
| [Java] HashMap vs ConcurrentHashMap 차이점 총정리 (언제 무엇을 써야 할까?) (0) | 2026.01.29 |
| [Java] HashMap Key로 객체를 사용할 때 꼭 알아야 할 equals()와 hashCode() (0) | 2026.01.29 |
| [Java] HashMap 사용방법과 꼭 알아야 할 주의사항 (개념, 특징, 메소드 및 예제) (0) | 2026.01.27 |